
2024年、生成AIと著作権を取り巻く環境は大きく動きました。文化庁による「AIと著作権に関する考え方について(素案)」のパブリックコメントを経て、3月には正式な考え方が示され、さらに7月には「AIと著作権に関するチェックリスト&ガイダンス」が公表されました。これにより、以前は曖昧だった「学習段階」と「生成・利用段階」における法的解釈がより明確化されています。
「知らなかった」では済まされないのが著作権侵害の怖いところです。企業活動において、あるいは個人のクリエイターとして、最新のルールを把握していないことは致命的なリスクになりかねません。本記事では、これら最新の2024年版ガイドラインに基づき、信頼できる情報を整理しました。生成AIを「安全に」「適法に」使いこなすための必須知識を、具体的なアクションと共に解説します。
1. 生成AIと著作権の基本を知る重要性
生成AIの技術革新は目覚ましく、ビジネスの現場でも日常的なツールとして定着しつつあります。しかし、その利便性の裏側には常に「他者の権利を侵害していないか?」という法的リスクが潜んでいます。特に2024年以降、権利者側からの懸念の声を受け、政府も「適正な利用」と「権利保護」のバランスを明確にする方向へ舵を切っています。
なぜ今、基本を知ることが重要なのでしょうか。それは、「AI生成物だから著作権フリー」という安易な認識が、重大な訴訟リスクや社会的信用の失墜を招くからです。既に海外では大規模な訴訟が起きており、日本国内でも無自覚な依拠(既存作品への類似)によるトラブルが懸念されています。
正しい知識を持つことは、単なるリスク回避だけではありません。「ここまでなら安全に使える」という境界線を知ることで、萎縮することなく最大限にAIのパワーをビジネスや創作に活かせるようになるのです。本記事で最新のルールを体系的に理解し、自信を持ってAIを活用できる状態を目指しましょう。
2. 生成AIにおける著作権の基本的な考え方
AIと著作権の関係を理解するためには、まず「AIが作ったものに権利は発生するのか(著作物性)」と「AIが学習することに問題はないのか(権利制限規定)」という2つの異なる側面を区別して考える必要があります。
2.1 生成AIが生成したコンテンツの著作権は誰のものか
結論から言えば、現在の日本の著作権法の解釈では、「AIが自律的に生成したコンテンツ」には、原則として著作権が発生しません。著作権法において著作物とは「思想又は感情を創作的に表現したもの」と定義されており、人間が思想感情を表現したものでなければならないからです。
しかし、これは「AIを使ったら一切著作権がない」という意味ではありません。文化庁の見解によれば、人間がAIを「道具」として使いこなし、そこに創作的寄与(創作意図と創作的活動)が認められる場合は、人間に著作権が発生する可能性があります。
具体的には以下の要素が重要視されます:
- 詳細な指示(プロンプト):単に「猫の絵を描いて」という短い指示ではなく、具体的な構図、色彩、光の当たり方などを詳細に指示した場合。
- 試行錯誤(ガチャではない):好みの結果が出るまで単に生成を繰り返すのではなく、意図する表現に近づけるためにプロンプトを修正し、何度も生成・選別を行うプロセス(いわゆる「人間による選択」の積み重ね)。
- 加筆・修正(人間による仕上げ):生成された画像に対して、Photoshop等のツールで人間が手を加えたり、修正したりした部分。
つまり、AIはあくまで「筆」や「カメラ」のような高度なツールであり、そこに「人間の創作的行為」が強く介在して初めて、その人間に権利が発生すると考えられています。
2.2 生成AIの学習データと著作権の関係性
次に、AIが既存の著作物を「学習」する行為についてです。日本の著作権法第30条の4は、世界的に見てもAI開発に有利な規定とされています。この条文により、「情報解析」などの目的であれば、原則として権利者の許諾なく著作物を利用(学習)できます。
ただし、ここには重要な例外規定(ただし書き)があります。それは「著作権者の利益を不当に害することとなる場合」です。2024年の文化庁の考え方では、この「不当に害する場合」の具体例として、「大量の特定クリエイターの作品だけを学習させ、そのクリエイターの作風を模倣した生成物を生成・提供する場合」などが挙げられています。
ここで重要なキーワードが「享受目的」と「非享受目的」です。
- 非享受目的(OK):データからルールやパターンを抽出するだけの情報解析。作品そのものを鑑賞・利用する意図がない場合。
- 享受目的(NG):学習データに含まれる特定の作品の表現を、そのまま出力させたり、その「良さ」を味わう目的で生成させる場合。
つまり、「学習データとして読み込ませること」自体は広く認められていますが、その目的が「特定の作品のコピーを作る(享受する)ため」であった場合、30条の4の対象外となり、著作権侵害となるリスクが発生します。
3. 知っておくべき生成AI利用時の著作権侵害リスク
「学習は適法」でも、「生成・利用」は別問題です。ここからは、実際にどのような行為が著作権侵害(アウト)になるのか、リスクの構造を解説します。
3.1 著作権侵害となる具体的なケースと事例
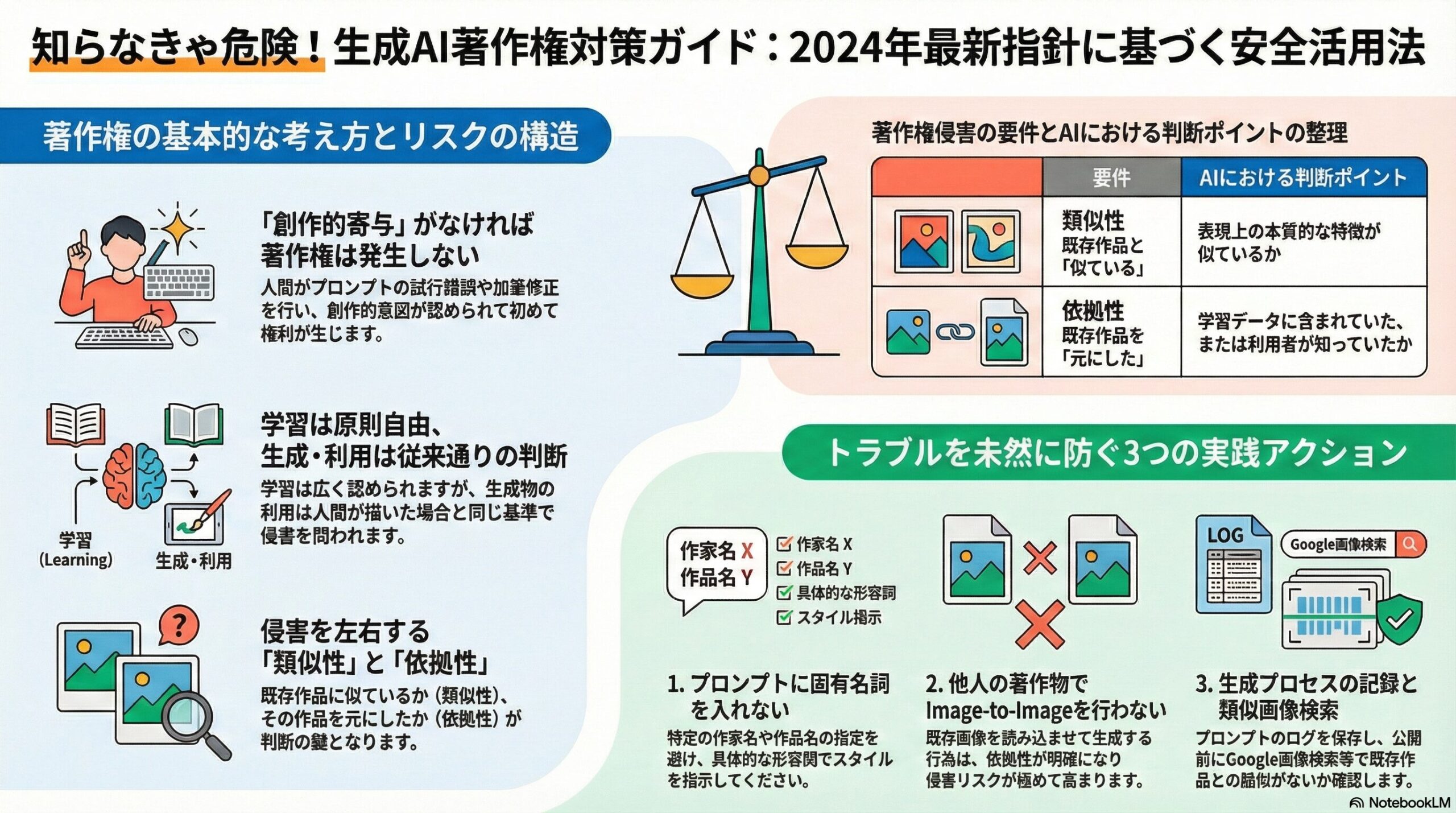
著作権侵害が成立するための2大要件は「依拠性(いきょせい)」と「類似性(るいじせい)」です。
| 要件 | 意味 | AIにおける判断ポイント |
|---|---|---|
| 類似性 | 既存の著作物と「似ている」こと | 表現上の本質的な特徴が似ているか。偶然の一致や、ありふれた表現の類似は含まれない。 |
| 依拠性 | 既存の著作物を「知っていて」「元にして」作ったこと | AI利用者がその作品を知っていたか、あるいはAIの学習データに含まれていたか。 |
具体的な侵害リスクが高いのは以下のようなケースです。
- Case 1: 特定作品の画風模倣(LoRA等の追加学習)
特定のイラストレーターの作品を大量に学習させ(追加学習)、その作家独特のタッチや画風を再現したイラストを生成し、商用利用する行為。これは「享受目的」の学習とみなされやすく、また生成物が類似していれば侵害となります。 - Case 2: Image-to-Image(i2i)での転用
ネット上の既存画像をAIに読み込ませ(i2i)、構図やポーズをそのまま維持した状態で別バージョンの画像を生成した場合。「依拠性」が明確であり、翻案権侵害となる可能性が高いです。 - Case 3: プロンプトでの固有名詞指定
「〇〇(有名キャラクター名)のような」や具体的な作品名をプロンプトに入力して生成した場合。意図的に依拠しているため、類似したものが生成されれば侵害責任を問われます。
3.2 日本における生成AI著作権の法的解釈と動向
2024年の文化庁の議論整理により、日本における法的解釈はより解像度が高まりました。特に重要なのは、開発者だけでなく「利用者(ユーザー)」としての責任範囲が明確にされた点です。
3.2.1 文化庁や政府の生成AI著作権ガイドラインのポイント
2024年3月の「AIと著作権に関する考え方について」および7月のガイダンスにおける最重要ポイントは以下の通りです。
- 学習段階と生成・利用段階の明確な分離:
- 「学習」は原則自由だが、「享受目的」が併存している場合はNG。
- 「生成・利用」段階では、従来の著作権侵害(人間が手で描いた場合)と同じ基準で判断される。つまり、「AIが勝手にやった」という言い訳は通用しません。
- 海賊版データの学習リスク:学習データ収集時に、明らかに海賊版(違法アップロード)だと知りながら収集する行為は、権利侵害のリスクが高いとの見解が示されています。
- 依拠性の推定:AI利用者が元の作品を知らなくても、「AIの学習データにその作品が含まれていた」事実があれば、依拠性が推認される可能性があります。これは利用者にとって大きなリスクであり、利用するモデルの透明性が問われる理由となります。
4. 生成AIの著作権トラブルを未然に防ぐための実践ガイドライン
法的リスクを理解した上で、私たち利用者はどのような対策を取ればよいのでしょうか。文化庁の「チェックリスト」等を参考に、現場で実践すべき具体的なアクションプランを提示します。
4.1 学習データ選定とプロンプト入力の注意点
トラブルの種は「入口(学習・入力)」にあります。ここをコントロールすることが第一の防壁です。
4.1.1 学習データ選定における注意点
もしあなたが独自モデルを開発したり、追加学習(ファインチューニング)を行う立場なら、学習データセットのクリーンさが命です。
- クリーンなデータセットの利用:Adobe Fireflyのように、権利関係がクリアな画像のみで学習された商用モデルを選択する。
- オプトアウトの確認:学習データとしての利用を拒否(オプトアウト)しているサイトや作家の作品を、スクレイピング等で収集しないよう技術的な配慮を行う。
4.1.2 プロンプト入力における注意点
通常のユーザーにとって最も重要なのがここです。プロンプトによる指示は「侵害の指示」になり得ます。
- 作家名・作品名を入れない:「〇〇風」「〇〇(作品名)のスタイルで」といった固有名詞は絶対に入れない。スタイルを模倣したい場合は、具体的な形容詞(「パステルカラーで」「厚塗りの油絵風で」など)で言語化する。
- 既存作品をアップロードしない:「この画像の雰囲気に似せて」と他人の著作物をアップロード(Image-to-Image)するのは極めて高リスクです。参照画像は自社の資産か、権利フリーのものに限るべきです。
4.2 生成物の利用範囲と確認すべき利用規約
生成された画像やテキストを使う前に、必ず通過すべきチェックゲートがあります。
4.2.1 利用規約で確認すべき主なポイント
サービスごとにルールは異なります。以下の項目は必ず約款(ToS)で確認してください。
| 確認項目 | チェックポイント |
|---|---|
| 商用利用権 | 無料プランでは商用利用NGで、有料プランのみOKというケースが多いです。今のプランで許可されているか? |
| 権利の帰属 | 生成物の権利はユーザーにあるのか、プラットフォームにあるのか?(多くの主要サービスはユーザーに権利を譲渡する形をとっています) |
| 免責事項 | 「第三者の権利を侵害した場合、ユーザーが全責任を負う」という条項が入っているのが一般的です。プラットフォームは守ってくれないと考えましょう。 |
4.3 商用利用と個人利用で異なる著作権の扱い
最後に、利用シーン別の温度感の違いを整理します。
4.3.1 個人利用の場合
個人的または家庭内などの限られた範囲で使用する場合(私的使用)は、著作権法上の例外として複製等が認められる範囲が広いです。ただし、SNSへの投稿は「個人利用」の範囲を超え「公衆送信」となります。個人的な趣味で作ったファンアートであっても、AI生成物をネットに公開する際は、他者の権利を侵害していないか厳重な注意が必要です。
4.3.2 商用利用の場合
企業サイト、広告、販売物などの商用利用では、侵害時の賠償額も大きくなります。以下の「リスク低減プロセス」を業務フローに組み込むことを推奨します。
- 生成過程の記録:どのようなプロンプトを入力したか、参照画像は使っていないか、生成のログ(履歴)を保存しておく。これは将来「依拠性」を否定するための証拠になります。
- 類似性調査(類似画像検索):Google画像検索などで生成画像を検索し、酷似している既存作品が存在しないか確認する。
- 社内ガイドラインの策定:従業員が勝手に無料ツールで生成した素材を使わないよう、利用可能なAIツールと利用ルールを明確化する。
5. まとめ
2024年の文化庁ガイドライン公表により、生成AIの著作権問題は「無法地帯」から「ルールの整備された活用フェーズ」へと移行しました。「AI学習自体は柔軟に認めつつ、生成物の類似性には厳格に対処する」というのが現在の日本のスタンスです。
恐れる必要はありません。他者の権利を尊重する(特定の画風を狙い撃ちで模倣しない、既存作品を安易に下敷きにしない)という、クリエイティブの当たり前のマナーを守っていれば、過度に萎縮する必要はないのです。
正しい法的知識と、適切なAI活用スキルを武器に、AIという強力なパートナーをビジネスや創作活動に最大限役立ててください。






コメント